
Иногда при разработке сайта или приложения возникает необходимость создать обширную базу данных из справочников или сайтов, но копировать каждую запись из тысячи страниц может занять недели времени и давно уже не используется. Для автоматизации данного процесса существует множество софта для парсинга, которые выполняет сбор всего за несколько минут/часов. Но использование подобного софта новичкам просто невозможно из-за наличия в них кучи настроек, к которым нету нормальных инструкций, по этому я попытаюсь рассказать как настроить и использовать самый универсальный парсер сайтов, который пригодится вам как для наполнения сайтов/приложений, так и сбора иных данных - адресов,телефонов и т.д. (для маркетинга),а в конце вы найдёте видео со всеми настройками.
Для своей работы и создания приложений я долго выискивал хороший парсер, но чаще всего они встречаются заточенными всего для одного ресурса и для одной цели, дабы упросить работу с ним, создав всего одну кнопку “Сделать все за меня”. Но пока ни разу у меня не возникло необходимости их использовать и собирать данные с вконтакте (комментариев к записям мдк) или обсуждения на мейл.ру о новой куртке Джастина Бибера. Потому найдя парсер ContentDownloader – моему счастью не было придела, так как он является универсальным, то есть настроив его он способен собрать данные практически с любого ресурса. К тому же для него существует куча (платных) плагинов, уже настроенных на сбор определенных сведений, телефонов, email-адресов, записей к блогам и т.д., но при наличии умения настройки данного приложения, плагины вам не потребуются.
Для начала необходимо скачать сам ContentDownloader с официального сайта (бета-версию или купить лицензию), либо же найти в сети старую версию с кряком (естественно только для ОЗНАКОМИТЕЛЬНЫХ целей).
Для разбора настройки данной софтины я решил использовать сайт автомобильной тематики и собрать данные по существующим на рынке автомобилям и их ценам, к слову в итоге можно получить неплохую базу данных для подбора автомобиля либо для слежения динамики роста цен на них.
Шаг 1.
Открываем необходимый ресурс и переходим на страницу списка элементов, которые мы будем парсить, в данном случае это страница http://www.avtobazar.ru/ . На этой странице мы попадем на сам сайт продажи автомобилей, но нам необходимо попасть на страницу со списком автомобилей, по этому мы перейдем на страницу поиска нажав соответствующую кнопку на сайте, но не вводя никаких данных, чтобы отобразились все автомобили, либо же введём параметры поиска, например год выпуска, чтоб получить список только за необходимый год.Адрес страницы со списком выглядит примерно так http://www.avtobazar.ru/autos/search/?f%5Bcity%5D=1&f%5Bmark%5D=&f%5
Bprice_from%5D=&f%5Bprice_to%5D=
&f%5Bcurrency%5D=RUR&f%5Byear_
from%5D=&f%5Byear_to%5D= и включает в себя множество параметров, но для нас будет важным только один – номер страницы на которой мы находимся. Для появления этого параметра перейдем на вторую страницу http://www.avtobazar.ru/autos/search/?f[city]=1&f[mark]=&f[price_from]=&f[price_to]
=&f[currency]=RUR&f[year_from]=&f[year_to]=&f[page]=1 .
Шаг 2.
Открываем ContentDownloader и копируем найденный адрес сайта в поле указанное ниже, предварительно заменив номер страницы на такой параметр {num} в итоге у нас выйдет следующая ссылка http://www.avtobazar.ru/autos/search/?f[city]=1&f[mark]=&f[price_from]=
&f[price_to]=&f[currency]=RUR&f
[year_from]=&f[year_to]=&f[page]={num} .
Данный параметр необходим для того, чтоб парсер подставил вместо него все номера страниц и не пришлось копировать отдельно каждую ссылку страницы.
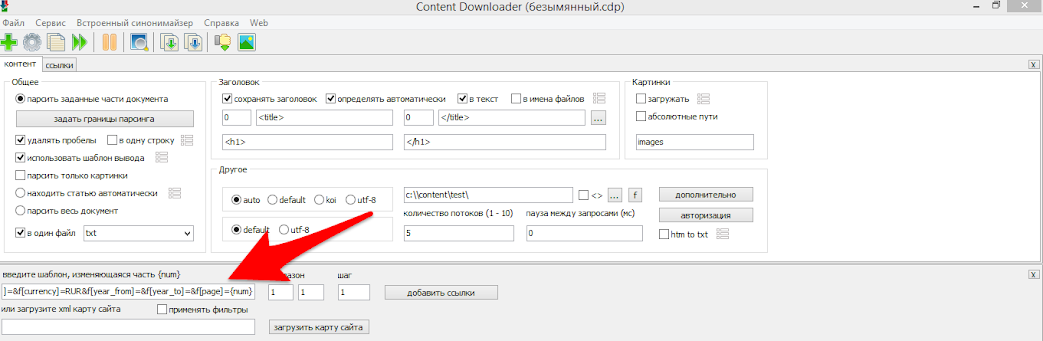
Шаг 3.
Задаем какой диапазон страниц мы будем использовать задав начальную, первую страницу(1) и последнюю страницу (90) в соответствующие поля. Шаг изменения параметра num указываем 1. В некоторых случаях номера страниц изменяются более чем на единицу, к примеру номер страниц могут быть следующие 0-5-10-15 и т.д., в таком случае шаг будет равен пяти. После чего добавляем к списку весь заданный диапазон. В итоге в нижней части экрана добавятся все ссылки на страницы из поиска.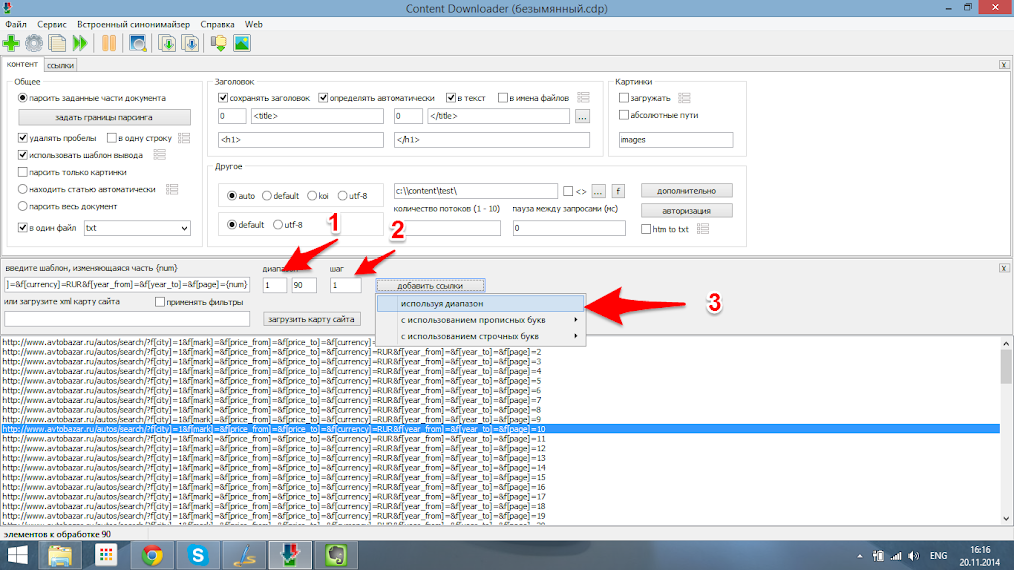
Шаг 4.
Хорошо, ссылки на страницы поиска у нас есть, но нас интересует не они,а ссылки на страницы самих автомобилей из этих страниц. Для их сбора нам нужно задать фильтр этих страниц. Для этого открываем список ссылок для любой из добавленных страниц перейдя на соответствующую вкладку и дважды нажав на любую добавленную страницу .
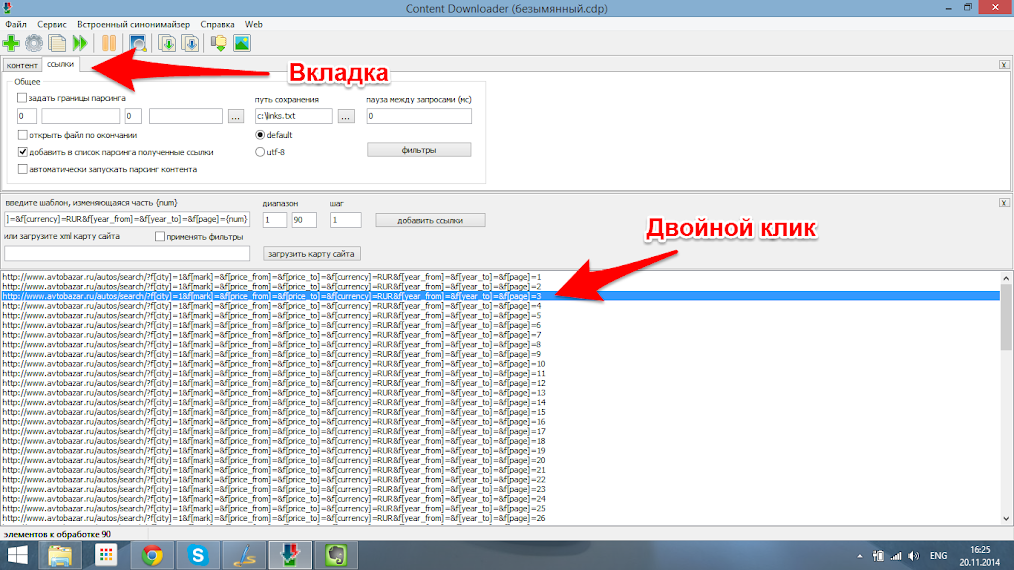
В открывшемся текстовом документы видно все ссылки на странице поиска, страницы каждого автомобиля имеют вид http://www.avtobazar.ru/autos/show/34177/ . В данном случае уникальной особенностью для страниц является часть http://www.avtobazar.ru/autos/show/ . Копируем его и добавляем в фильтр, указав отбирать только ссылки с этой частью.
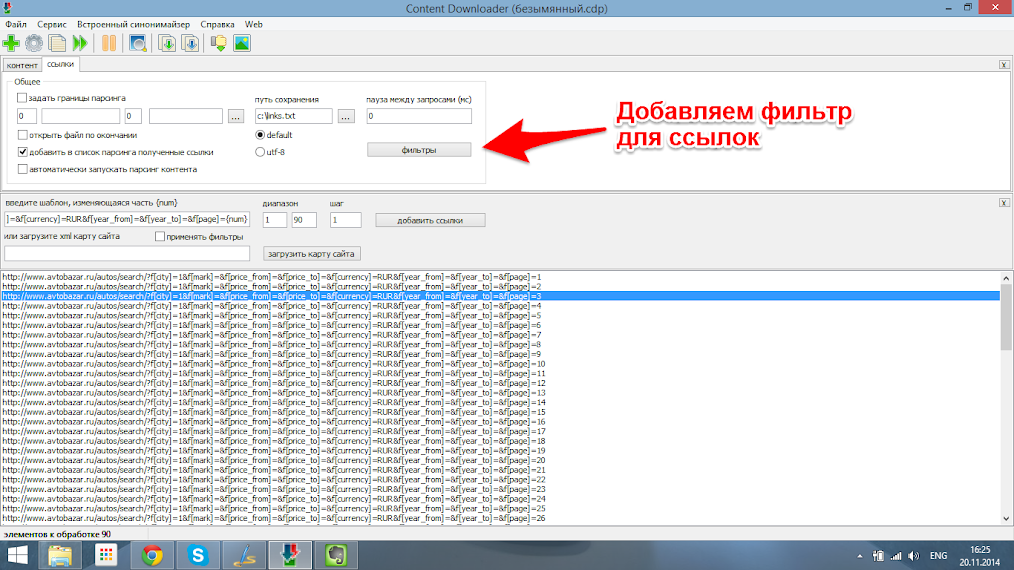
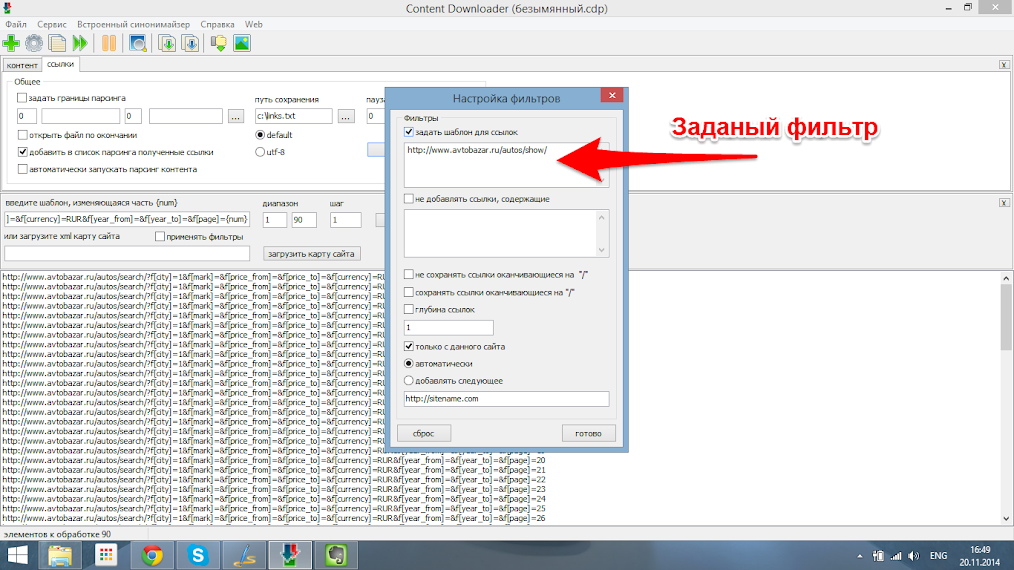
Шаг 5.
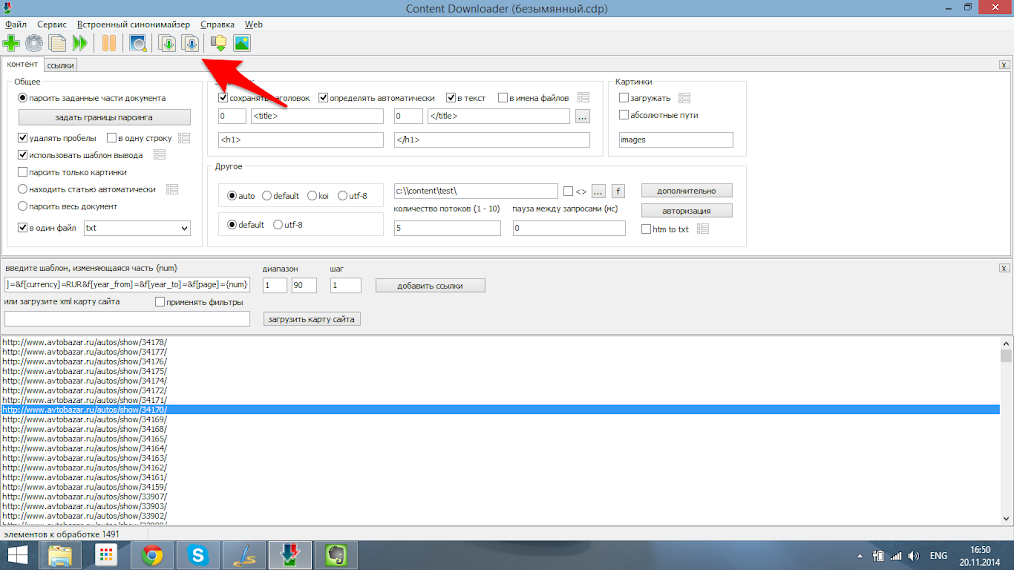
Следующим шагом нам необходимо с каждой страницы поиска выбрать ссылки на конкретные автомобили, выбрав соответствующий пункт меню.
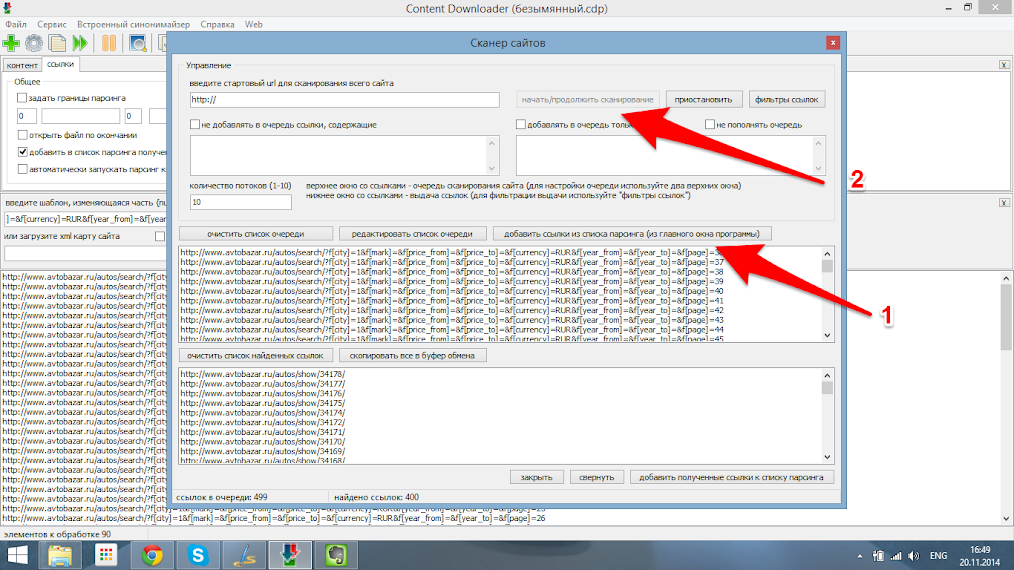
В открывшемся окне добавляем найденные страницы (1) и запускаем сбор ссылок (2).
Шаг 6.
После того как все ссылки будут собраны нам необходимо удалить все страницы поиска из главного окна, нажав на них правой кнопкой и выбрав пункт меню “Очистить список” и вставить найденные ссылки из окна поиска ссылок как указано ниже.
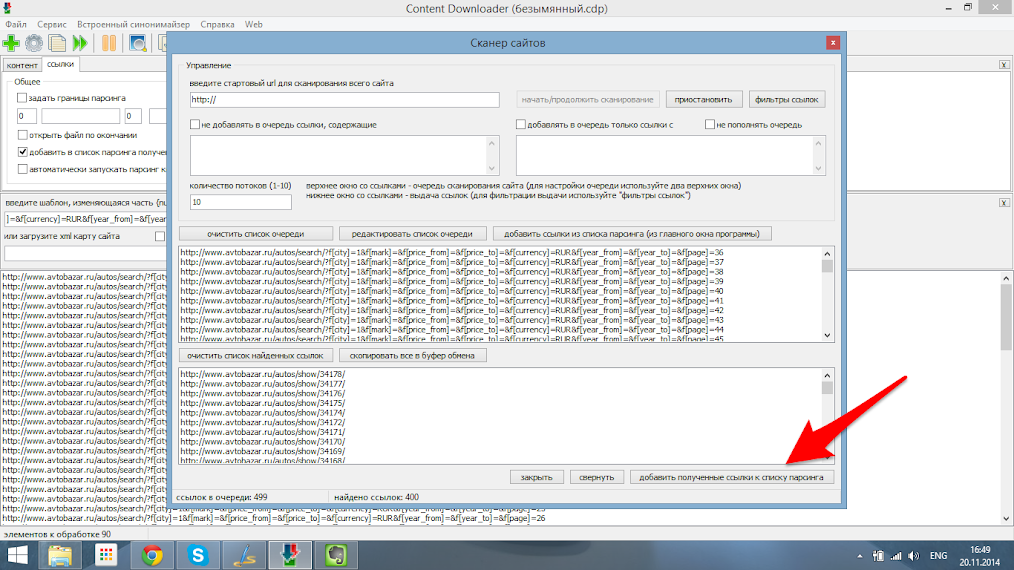
Шаг 7.
Теперь мы получили именно то, что нам нужно было,а именно все ссылки на страницы автомобилей, которые есть на сайте. Теперь выделим какие именно данные нам нужно забрать с этих страниц, для этого возвращаемся на первую вкладку главного окна (1 “контент”) и нажимаем “задать границы парсинга” (2).
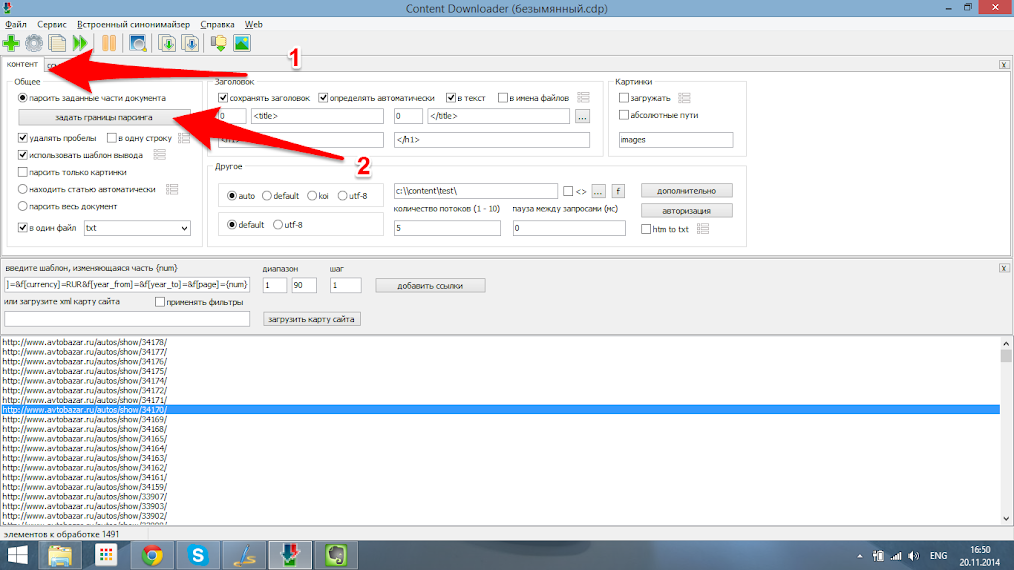
Шаг 8.
В открывшемся окне жмём кнопку с троеточием напротив первого параметра.
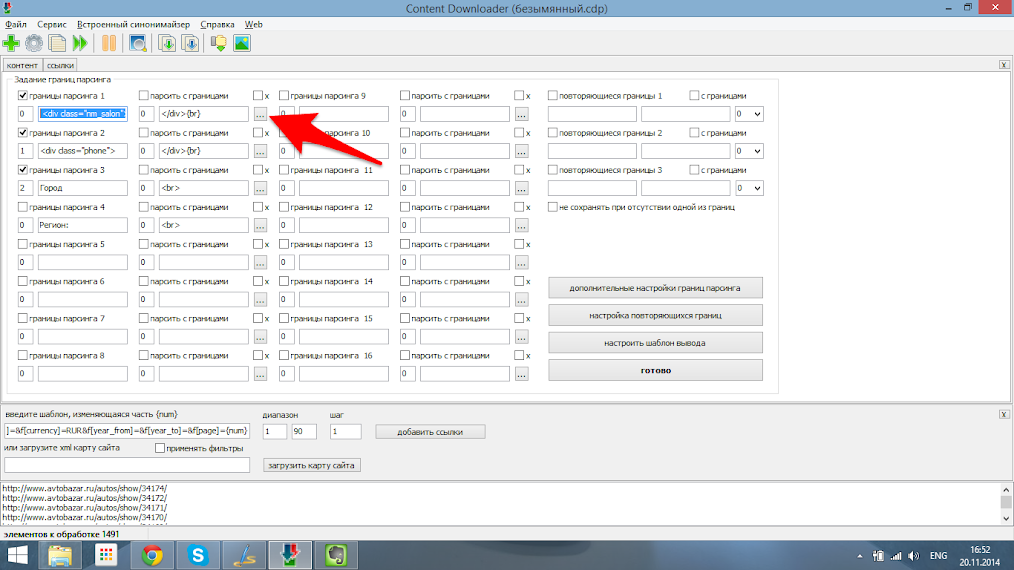
В открывшемся окне нам необходимо найти место, где указано название автомобиля и выделить уникальные html теги в которые оно заключено. После чего нажимаем “Готово”. Для задания границ второго параметра (цены) выполняем аналогичные действия.
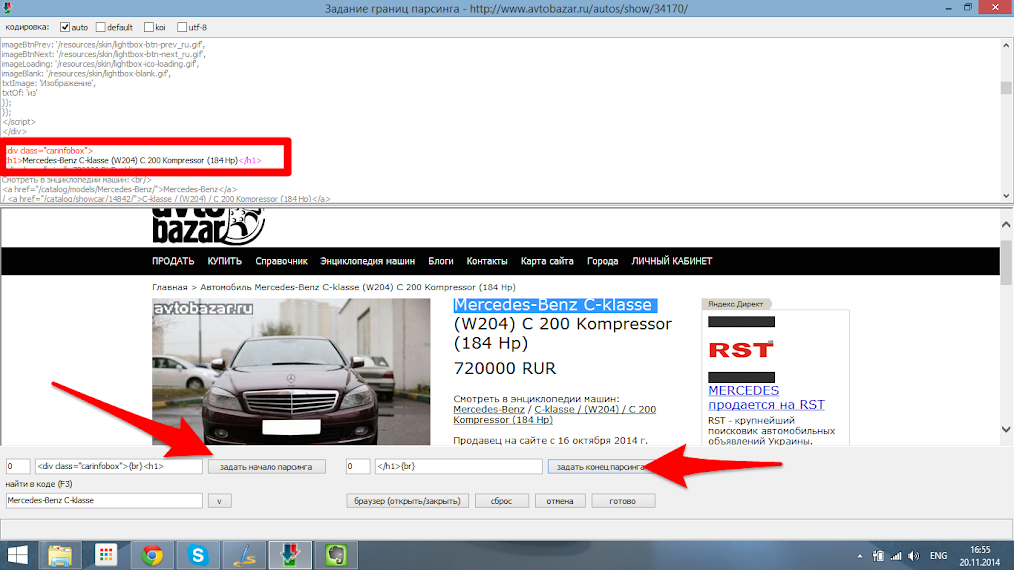
Далее нажав в том же окне кнопку “Настроить шаблон вывода” настраиваем вид, в котором мы получим данные. Задаем два значения которые нам требуется я рекомендую разделить их знаком “;” , так как в дальнейшем это может понадобится для импорта полученных данных в базу данных, например таблицу Exel или SQL.
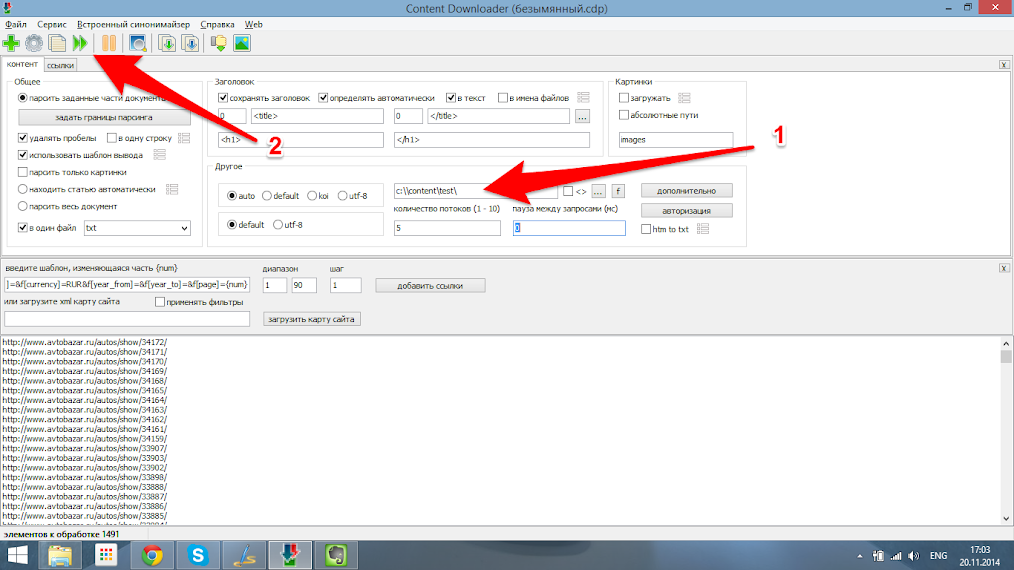
Шаг 9.
Вот и все, парсер настроен и нам осталось только указать место, куда будет сохранён результат(1) и запустить парсер (2). После завершения работы программы переходим в папку назначения и увидим готовый результат вида :
Mazda Xedos 6 (CA) 2.0 V6 (144 Hp) ; 170000 RUR
Kia Cee'd II 1.6i (122Hp) ; 660000 RUR
Mazda Mazda 6 Sedan (GG,GY) 2.3 16V (166 Hp) ; 253000 RUR
Mazda Xedos 6 (CA) 2.0 V6 (144 Hp) ; 170000 RUR
Mercedes-Benz S-klasse (W221) S 500 Lang (388 Hp) ; 950000 RUR
Mercedes-Benz ; 1925000 RUR
Mercedes-Benz C-klasse (W204) C 200 Kompressor (184 Hp) ; 720000 RUR
Mercedes-Benz ; 1345000 RUR
Как можно увидеть, данный способ настраивается под любые нужды, любое количество данных и виды сайта. Разобравшись на подобном примере и поняв логику работы данной программы, вы сможете собирать необходимые вам данные абсолютно с любого сайта, будь то для наполнения ваших разработок или же в целях маркетинга(фу-фу-фу как нехорошо).
Комментариев нет:
Отправить комментарий